Mixture-of-Experts
Mixture-of-Experts (MoE) is a special model structure. MoE partitions the model into a series of sub-models called “experts”, each with unique parameters. MoE only activates one or a small number of experts for each input token. For example, the figure switch transformer shows the sparse MoE architecture proposed by Switch Transformer . The Forward Neural Network (FFN) is decomposed into multiple sub-networks, and only a small number of model parameters are involved in the calculation to achieve more efficient calculation and resource allocation.
Sparse MoE usually also includes a gating mechanism, such as the Router in Figure switch transformer . The gating network is responsible for selecting which experts to activate and combining the prediction results of different experts.
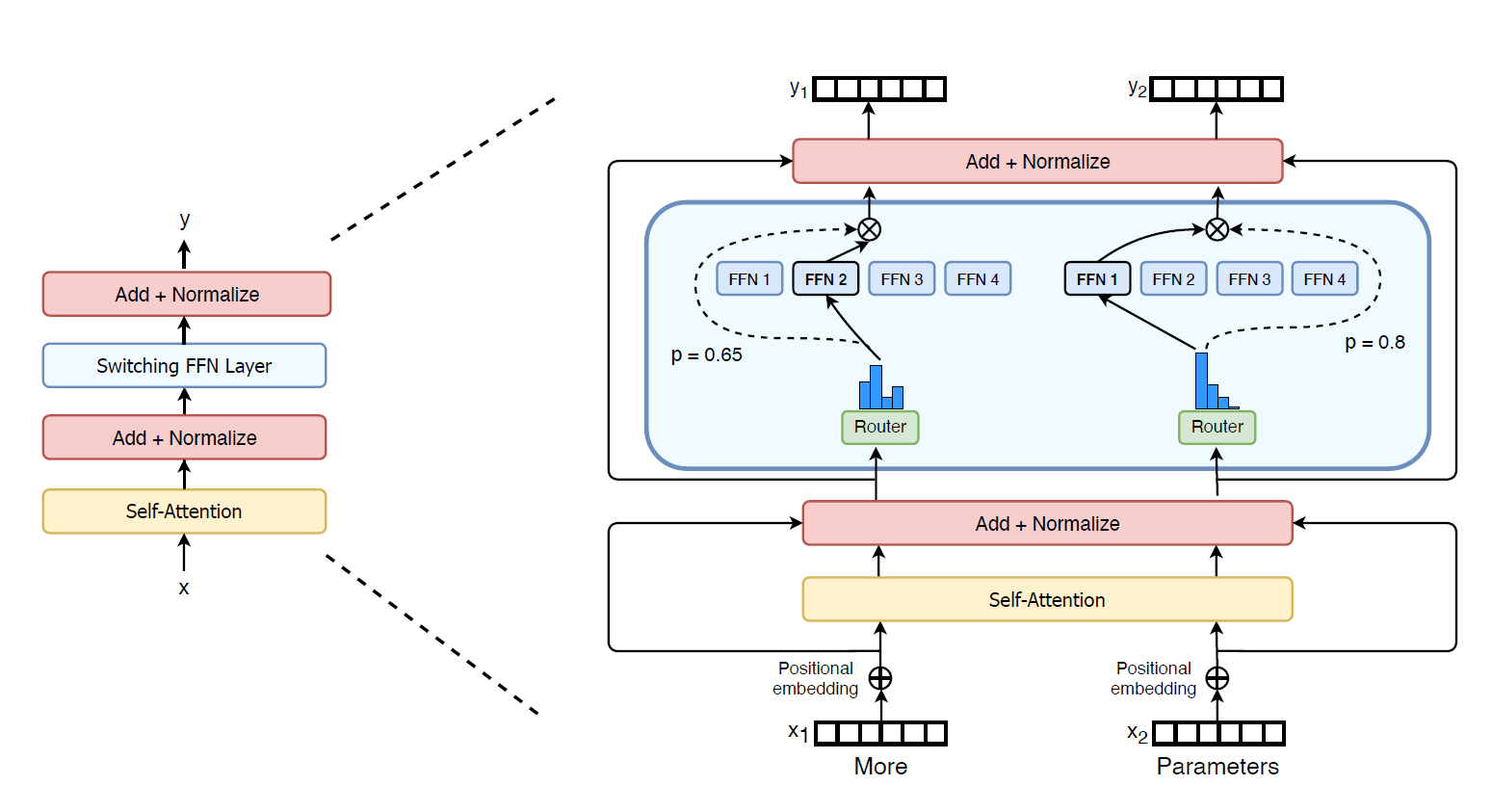
switch transformer
Parameter Settings
If MoE is expected to be used in the training, please make the following settings in the configuration file:
Model related settings
model = dict(
num_experts=16,
moe_gate_k=1,
)
num_experts: The number of expert networks. In InternEvo, each expert has the same network structure but maintains different training parameters.
moe_gate_k: Gating strategy. Determines how to route input tokens to different experts for calculation. Currently, InternEvo supports top1gating and top2gating strategies. For detailed information about these gating strategies, please refer to GShard.
Note: In the current version of InternEvo, each expert is a SwiGLU network based on HIDDEN_SIZE and MLP_RATIO in the configuration file, and supports tensor parallelism. Users can construct their own expert networks as needed.
Loss related settings
loss = dict(
moe_loss_coeff=0.1,
)
In top1gating and top2gating strategies, the number of tokens to process may be different for different experts. In order to improve the model effect, the input tokens should be evenly routed to different experts. InternEvo adopts the balancing loss to optimize the gating network proposed by GShard. The moe_loss_coeff determines how the balancing loss should be added to the final loss ( \(l=l_{nll}+k·l_{moe}\) ). The details can be found in GShard.
Note: These parameters need to be used together with other parameters, please refer to Quickstart Guide: Training Configuration
Model Training
internlm.model.modeling_moe provides an implementation of a standard MoE. The model structure is consistent with Figure switch transformer , which uses internlm.model.moe.MoE to implement the MoE network. To use moe model, specify the model type in the configuration file:
model_type = "INTERNLM_MoE"
After configuring the relevant parameters of the sparse MoE, the distributed training can start as the normal training process. please refer to Quickstart Guide: Start Training
Note: InternEvo supports users to define their own MoE structure. internlm.model.moe.MoE is the interface that defines the MoE network. Currently, the SwiGLU network is used to implement the experts and supports two gating strategies: top1gating and top2gating. Users can extend the expert network and gating strategy in the MoE interface as needed.