Mixed Precision
Mixed precision refers to using both 16-bit and 32-bit floating-point types to train model, which can accelerate the model training while minimizing the accuracy loss. Mixed precision training uses 32-bit floating-point types in certain parts of the model to maintain numerical stability, and accelerate training and reduce memory usage by using 16-bit floating-point types in other parts. Mixed precision can achieve the same training effect in evaluating indicators such as accuracy.
- class internlm.core.naive_amp.NaiveAMPModel(*args: Any, **kwargs: Any)[source]
This is a wrapper class for a model that automatically casts the model, its inputs, and outputs into fp16. It also provides options to cast the output back to fp32 and to synchronize buffers.
- Parameters:
model (torch.nn.Module) – The model to be wrapped and cast into fp16.
output_to_fp32 (bool, optional) – If True, the output of this module is cast into fp32. Defaults to True.
parallel_mode (
internlm.core.context.ParallelMode) – The parallel group mode used in this module. Defaults toParallelMode.DATA.sync_buffer (bool, optional) – If True, the buffers are synchronized. Defaults to True.
InternEvo converts the model to 16-bit floating-point types for model training by default (the default type can be set to other data types in the configuration file). When using mixed precision, it is necessary to use
set_fp32_attr_to_module(/*fp32 module*/)
to set a sub-module of the model to 16-bit floating-point types for training, and InternEvo will automatically convert the data type to the required precision during model training.
For example:
class MlpModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(4, 1, bias=False)
self.linear2 = nn.Linear(1, 4, bias=False)
# set model.linear2 as fp32 module
set_fp32_attr_to_module(model.linear2)
model = MlpModel()
# apply mixed precision
model = NaiveAMPModel(
model=model,
output_to_fp32=True,
dtype=torch.bfloat16(),
sync_buffer=False,
)
TF32 Training
TensorFloat-32 (TF32) is a computational format introduced by Nvidia on Ampere Architecture GPUs for TensorCore. A comparison with other data formats is shown below.
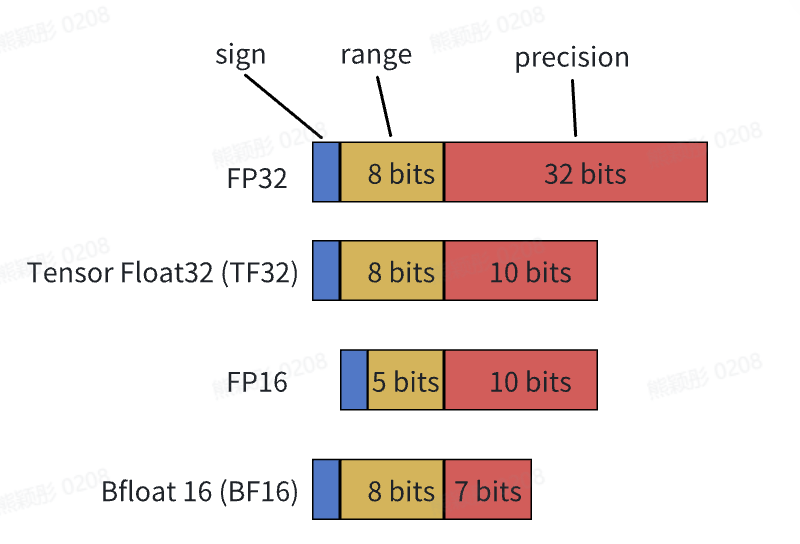
Prerequisites for using TF32.
The input data type should be FP32 and TF32 is designed for matrix multiplication, convolutions, and other relative computations.
Ampere Architecture GPU
InternEvo supports training model in TF32 and allows user to set the dtype in config as torch.tf32.
model = dict(
checkpoint=False, # The proportion of layers for activation aheckpointing, the optional value are True/False/[0-1]
num_attention_heads=NUM_ATTENTION_HEAD,
embed_split_hidden=True,
vocab_size=VOCAB_SIZE,
embed_grad_scale=1,
parallel_output=True,
hidden_size=HIDDEN_SIZE,
num_layers=NUM_LAYER,
mlp_ratio=MLP_RATIO,
apply_post_layer_norm=False,
dtype="torch.tf32", # Support: "torch.float16", "torch.half", "torch.bfloat16", "torch.float32", "torch.tf32"
norm_type="rmsnorm",
layer_norm_epsilon=1e-5,
use_flash_attn=True,
num_chunks=1, # if num_chunks > 1, interleaved pipeline scheduler is used.
)
It is noticed that TF32 is an intermediate format in TensorCore instead of a data type. Therefore, InternEvo could set the following environment variables to enable TF32 when the dtype is torch.tf32, which is actually torch.float32.
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True