Training Setup
The training process of InternEvo can be summarized into two steps:
Initialization
Initialize model, optimizer, dataloader, trainer, and create different types of process groups to prepare for iterative steps of hybrid parallel training.
Initialize logger, checkpoint manager, monitor manager, and profiler to watch, alert, and record the iterative training steps.
Iterative training steps
Load the training engine and scheduler for hybrid parallel training according to the configuration such as tensor parallel size, pipeline parallel size, and data parallel size.
In iterative training steps, the Trainer API is called to perform zero gradients, forward-loss-backward, and parameter update.
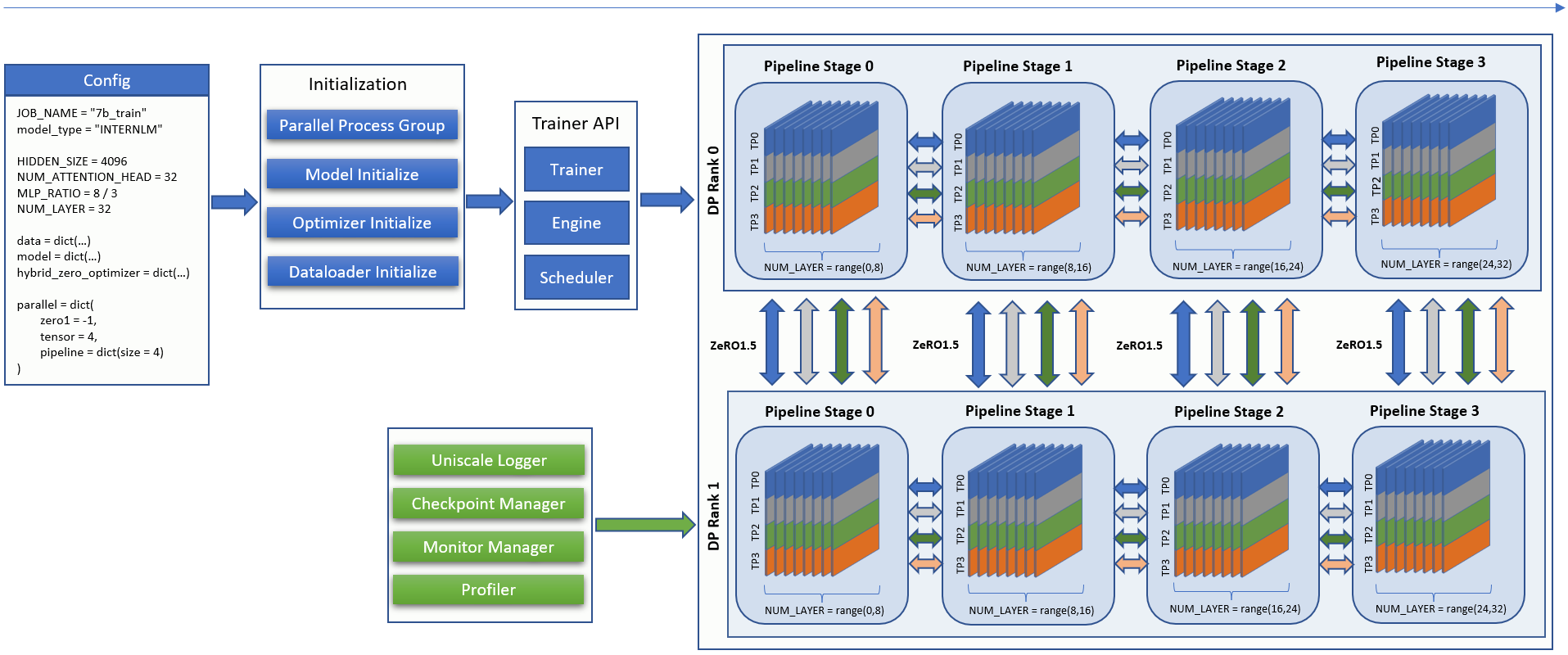
InternEvo training process
Argument Parsing
InternEvo uses the argparse library to supply commandline configuration to the InternEvo runtime.
Use internlm.initialize.get_default_parser() to get InternEvo’s default parser with some builtin arguments, users can add custom parameters to this parser.
# Get InternEvo default parser
parser = internlm.initialize.get_default_parser()
# Add new argument
parser.add_argument("--user_arg", type=int, default=-1, help="arguments add by user.")
cmd_args = parser.parse_args()
Model Initialization
InternEvo uses the field model_type and model in the config file to control model initialization process. An example model initialization configuratio
model_type = "INTERNLM" # default is "INTERNLM", used to register classes and modules for model initialization
NUM_ATTENTION_HEAD = 32
VOCAB_SIZE = 103168
HIDDEN_SIZE = 4096
NUM_LAYER = 32
MLP_RATIO = 8 / 3
model = dict(
checkpoint=False, # The proportion of layers for activation aheckpointing, the optional value are True/False/[0-1]
num_attention_heads=NUM_ATTENTION_HEAD,
embed_split_hidden=True,
vocab_size=VOCAB_SIZE,
embed_grad_scale=1,
parallel_output=True,
hidden_size=HIDDEN_SIZE,
num_layers=NUM_LAYER,
mlp_ratio=MLP_RATIO,
apply_post_layer_norm=False,
dtype="torch.bfloat16", # Support: "torch.float16", "torch.half", "torch.bfloat16", "torch.float32", "torch.tf32"
norm_type="rmsnorm",
layer_norm_epsilon=1e-5,
use_flash_attn=True,
num_chunks=1, # if num_chunks > 1, interleaved pipeline scheduler is used.
)
The field
model_typespecifics the model type has been registered and to be initialized.The parameters in field
modelspecific the configuration settings during model initialization.
It is worth noting that, users can define new model type, and register model’s initialization function by decorater @MODEL_INITIALIZER.register_module, which MODEL_INITIALIZER is an instantiated object of class internlm.util.registry.Registry, the example is shown as follows.
MODEL_TYPE = "NEW_MODEL"
@MODEL_INITIALIZER.register_module(module_name=MODEL_TYPE)
def build_new_model_with_cfg(*args, **kwargs):